
Causality-Facilitated Reinforcement Learning
AdaRL: What, Where, and How to Adapt in Transfer Reinforcement Learning
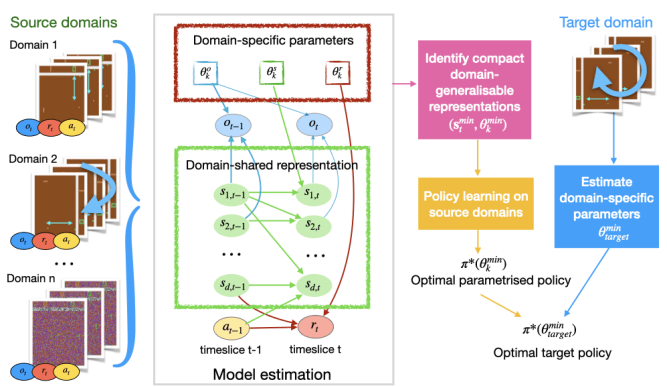
This work is on generalizing the learned policies to new environments in an efficient and effective way. Usually, distribution shifts are due to the changes of only a few mechanisms in the generative process, so we can just adapt the distribution corresponding to the generating process of a small portion of the variables. To this end, we leverage a graphical representation that characterizes structural relationships over variables in the RL system. Such graphical representations provide a compact way to encode where the changes are and inform us with a minimal set of changes that one needs to consider for policy adaptation, so that we can efficiently adapt the policy to the target domain, where only a few samples are needed and further policy optimization is avoided. [paper][ code ]
Identifiable State Factorizations in Reinforcement Learning
- Learning World Models with Identifiable Factorization. [pdf]
- Action-Sufficient State Representation Learning for Control with Structural Constraints. [pdf]
Extracting a stable and compact representation of the environment is crucial for efficient reinforcement learning in high-dimensional, noisy, and non-stationary environments. Different categories of information coexist in such environments – how to effectively extract and disentangle these information remains a challenging problem. In this paper, we propose IFactor, a general framework to model four distinct categories of latent state variables that capture various aspects of information within the RL system, based on their interactions with actions and rewards. Our analysis establishes block-wise identifiability of these latent variables, which not only provides a stable and compact representation but also discloses that all reward-relevant factors are significant for policy learning. We further present a practical approach to learning the world model with identifiable blocks, ensuring the removal of redundants but retaining minimal and sufficient information for policy optimization. Experiments in synthetic worlds demonstrate that our method accurately identifies the ground-truth latent variables, substantiating our theoretical findings.

Factored Adaptation for Non-Stationary Reinforcement Learning
Dealing with non-stationarity in environments (e.g., in the transition dynamics) and objectives (e.g., in the reward functions) is a challenging problem that is crucial in real-world applications of reinforcement learning (RL). While most current approaches model the changes as a single shared embedding vector, we leverage insights from the recent causality literature to model non-stationarity in terms of individual latent change factors, and causal graphs across different environments. In particular, we propose Factored Adaptation for Non-Stationary RL (FANS-RL), a factored adaption approach that learns jointly both the causal structure in terms of a factored MDP, and a factored representation of the individual time-varying change factors. We prove that under standard assumptions, we can completely recover the causal graph representing the factored transition and reward function, as well as a partial structure between the individual change factors and the state components. Through our general framework, we can consider general non-stationary scenarios with different function types and changing frequency, including changes across episodes and within episodes. [pdf]
Sample-Efficient Reinforcement Learning via Counterfactual-based Data Augmentation
RL algorithms usually require a substantial amount of interaction data and perform well only for specific tasks in a fixed environment. In some scenarios such as healthcare, however, usually only few records are available for each patient, and patients may show different responses to the same treatment, impeding the application of current RL algorithms to learn optimal policies. To address the issues of mechanism heterogeneity and related data scarcity, we propose a data-efficient RL algorithm that exploits structural causal models (SCMs) to model the state dynamics, which are estimated by leveraging both commonalities and differences across subjects. The learned SCM enables us to counterfactually reason what would have happened had another treatment been taken. It helps avoid real (possibly risky) exploration and mitigates the issue that limited experiences lead to biased policies. We propose counterfactual RL algorithms to learn both population-level and individual-level policies. We show that counterfactual outcomes are identifiable under mild conditions and that Q-learning on the counterfactual-based augmented data set converges to the optimal value function. [pdf]
Boosting Efficiency in Task-Agnostic Exploration Through Causal Knowledge
The effectiveness of model training heavily relies on the quality of available training resources. However, budget constraints often impose limitations on data collection efforts. To tackle this challenge, we introduce causal exploration in this paper, a strategy that leverages the underlying causal knowledge for both data collection and model training. We, in particular, focus on enhancing
the sample efficiency and reliability of the world model learning within the domain of task-agnostic reinforcement learning. During the exploration phase, the agent actively selects actions expected to yield causal insights most beneficial for world model training. Concurrently, the causal knowledge is acquired and incrementally refined with the ongoing collection of data. We demonstrate that causal exploration aids in learning accurate world models using fewer data and provides theoretical guarantees for its convergence. [pdf]
Interpretable Reward Redistribution in Reinforcement Learning: A Causal Approach.
A major challenge in reinforcement learning is to determine which state-action pairs are responsible for future rewards that are delayed. Reward redistribution serves as a solution to re-assign credits for each time step from observed sequences. While the majority of current approaches construct the reward redistribution in an uninterpretable manner, we propose to explicitly model the contributions of state and action from a causal perspective, resulting in an interpretable reward redistribution and preserving policy invariance. In this paper, we start by studying the role of causal generative models in reward redistribution by characterizing the generation of Markovian rewards and trajectory-wise long-term return and further propose a framework, called Generative Return Decomposition (GRD), for policy optimization in delayed reward scenarios. Specifically, GRD first identifies the unobservable
Markovian rewards and causal relations in the generative process. Then, GRD makes use of the identified causal generative model to form a compact representation to train policy over the most favorable subspace of the state space of the agent. Theoretically, we show that the unobservable Markovian reward function is identifiable, as well as the underlying causal structure and causal models. Experimental results show that our method outperforms state-of-the-art methods and the provided visualization further demonstrates the interpretability of our method. [pdf]
ACAMDA: Improving Data Efficiency in Reinforcement Learning Through Guided Counterfactual Data Augmentation
Data augmentation plays a crucial role in improving the data efficiency of reinforcement learning (RL). However, the generation of high-quality augmented data remains a significant challenge. To overcome this, we introduce ACAMDA (Adversarial Causal Modeling for Data Augmentation), a novel
framework that integrates two causality-based tasks: causal structure recovery and counterfactual estimation. The unique aspect of ACAMDA lies in its ability to recover temporal causal relationships from limited non-expert datasets. The identification of the sequential cause-and-effect allows the creation of realistic yet unobserved scenarios. We utilize this characteristic to generate guided counterfactual datasets, which, in turn, substantially reduces the need for extensive data collection. By simulating various state-action pairs under hypothetical actions, ACAMDA enriches the training dataset for diverse and heterogeneous conditions. [pdf]
